Pseudogene
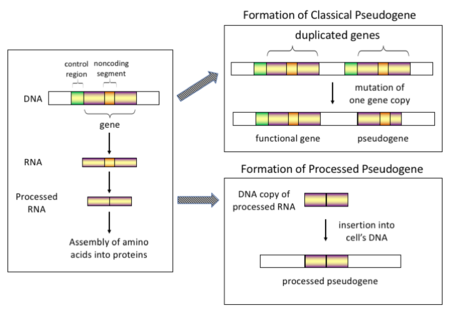
Mechanism of classical and processed pseudogene formation[1][2]
Pseudogenes, sometimes referred to as zombie genes in the media, are segments of DNA that are related to real genes. Pseudogenes have lost at least some functionality, relative to the complete gene, in cellular gene expression or protein-coding ability.[3] Pseudogenes often result from the accumulation of multiple mutations within a gene whose product is not required for the survival of the organism, but can also be caused by genomic copy number variation (CNV) where segments of 1+ kb are duplicated or deleted.[4] Although not fully functional, pseudogenes may be functional, similar to other kinds of noncoding DNA, which can perform regulatory functions. The "pseudo" in "pseudogene" implies a variation in sequence relative to the parent coding gene, but does not necessarily indicate pseudo-function. Despite being non-coding, many pseudogenes have important roles in normal physiology and abnormal pathology.[5]
Although some pseudogenes do not have introns or promoters (such pseudogenes are copied from messenger RNA and incorporated into the chromosome, and are called "processed pseudogenes"),[6] others have some gene-like features such as promoters, CpG islands, and splice sites. They are different from normal genes due to either a lack of protein-coding ability resulting from a variety of disabling mutations (e.g. premature stop codons or frameshifts), a lack of transcription, or their inability to encode RNA (such as with ribosomal RNA pseudogenes). The term "pseudogene" was coined in 1977 by Jacq et al.[7]
Because pseudogenes were initially thought of as the last stop for genomic material that could be removed from the genome,[8] they were often labeled as junk DNA. Nonetheless, pseudogenes contain biological and evolutionary histories within their sequences. This is due to a pseudogene's shared ancestry with a functional gene: in the same way that Darwin thought of two species as possibly having a shared common ancestry followed by millions of years of evolutionary divergence, a pseudogene and its associated functional gene also share a common ancestor and have diverged as separate genetic entities over millions of years.
Contents
1 Properties
2 Types and origin
2.1 Processed
2.2 Non-processed
2.3 Unitary pseudogenes
2.4 Pseudo-pseudogenes
3 Examples of pseudogene function
4 Misidentified pseudogenes
5 Bacterial pseudogenes
6 See also
7 References
8 Further reading
9 External links
Properties
Pseudogenes are usually characterized by a combination of homology to a known gene and loss of some functionality. That is, although every pseudogene has a DNA sequence that is similar to some functional gene, they are usually unable to produce functional final protein products.[9] Pseudogenes are sometimes difficult to identify and characterize in genomes, because the two requirements of homology and loss of functionality are usually implied through sequence alignments rather than biologically proven.
- Homology is implied by sequence identity between the DNA sequences of the pseudogene and parent gene. After aligning the two sequences, the percentage of identical base pairs is computed. A high sequence identity means that it is highly likely that these two sequences diverged from a common ancestral sequence (are homologous), and highly unlikely that these two sequences have evolved independently (see Convergent evolution).
- Nonfunctionality can manifest itself in many ways. Normally, a gene must go through several steps to a fully functional protein: Transcription, pre-mRNA processing, translation, and protein folding are all required parts of this process. If any of these steps fails, then the sequence may be considered nonfunctional. In high-throughput pseudogene identification, the most commonly identified disablements are premature stop codons and frameshifts, which almost universally prevent the translation of a functional protein product.
Pseudogenes for RNA genes are usually more difficult to discover as they do not need to be translated and thus do not have "reading frames".
Pseudogenes can complicate molecular genetic studies. For example, amplification of a gene by PCR may simultaneously amplify a pseudogene that shares similar sequences. This is known as PCR bias or amplification bias. Similarly, pseudogenes are sometimes annotated as genes in genome sequences.
Processed pseudogenes often pose a problem for gene prediction programs, often being misidentified as real genes or exons. It has been proposed that identification of processed pseudogenes can help improve the accuracy of gene prediction methods.[10]
Recently 140 human pseudogenes have been shown to be translated.[11] However, the function, if any, of the protein products is unknown.
Types and origin
There are four main types of pseudogenes, all with distinct mechanisms of origin and characteristic features. The classifications of pseudogenes are as follows:
Processed

Processed pseudogene production
Processed (or retrotransposed) pseudogenes. In higher eukaryotes, particularly mammals, retrotransposition is a fairly common event that has had a huge impact on the composition of the genome. For example, somewhere between 30–44% of the human genome consists of repetitive elements such as SINEs and LINEs (see retrotransposons).[12][13] In the process of retrotransposition, a portion of the mRNA or hnRNA transcript of a gene is spontaneously reverse transcribed back into DNA and inserted into chromosomal DNA. Although retrotransposons usually create copies of themselves, it has been shown in an in vitro system that they can create retrotransposed copies of random genes, too.[14] Once these pseudogenes are inserted back into the genome, they usually contain a poly-A tail, and usually have had their introns spliced out; these are both hallmark features of cDNAs. However, because they are derived from an RNA product, processed pseudogenes also lack the upstream promoters of normal genes; thus, they are considered "dead on arrival", becoming non-functional pseudogenes immediately upon the retrotransposition event.[15] However, these insertions occasionally contribute exons to existing genes, usually via alternatively spliced transcripts.[16] A further characteristic of processed pseudogenes is common truncation of the 5' end relative to the parent sequence, which is a result of the relatively non-processive retrotransposition mechanism that creates processed pseudogenes.[17] Processed pseudogenes are continually being created in primates.[18] Human populations, for example, have distinct sets of processed pseudogenes across its individuals.[19]
Non-processed

One way a pseudogene may arise
Non-processed (or duplicated) pseudogenes. Gene duplication is another common and important process in the evolution of genomes. A copy of a functional gene may arise as a result of a gene duplication event caused by homologous recombination at, for example, repetitive sine sequences on misaligned chromosomes and subsequently acquire mutations that cause the copy to lose the original gene's function. Duplicated pseudogenes usually have all the same characteristics as genes, including an intact exon-intron structure and regulatory sequences. The loss of a duplicated gene's functionality usually has little effect on an organism's fitness, since an intact functional copy still exists. According to some evolutionary models, shared duplicated pseudogenes indicate the evolutionary relatedness of humans and the other primates.[20] If pseudogenization is due to gene duplication, it usually occurs in the first few million years after the gene duplication, provided the gene has not been subjected to any selection pressure.[21] Gene duplication generates functional redundancy and it is not normally advantageous to carry two identical genes. Mutations that disrupt either the structure or the function of either of the two genes are not deleterious and will not be removed through the selection process. As a result, the gene that has been mutated gradually becomes a pseudogene and will be either unexpressed or functionless. This kind of evolutionary fate is shown by population genetic modeling[22][23] and also by genome analysis.[21][24] According to evolutionary context, these pseudogenes will either be deleted or become so distinct from the parental genes so that they will no longer be identifiable. Relatively young pseudogenes can be recognized due to their sequence similarity.[25]
Unitary pseudogenes

2 ways a pseuogene may be produced
Various mutations (such as indels and nonsense mutations) can prevent a gene from being normally transcribed or translated, and thus the gene may become less- or non-functional or "deactivated". These are the same mechanisms by which non-processed genes become pseudogenes, but the difference in this case is that the gene was not duplicated before pseudogenization. Normally, such a pseudogene would be unlikely to become fixed in a population, but various population effects, such as genetic drift, a population bottleneck, or, in some cases, natural selection, can lead to fixation. The classic example of a unitary pseudogene is the gene that presumably coded the enzyme L-gulono-γ-lactone oxidase (GULO) in primates. In all mammals studied besides primates (except guinea pigs), GULO aids in the biosynthesis of ascorbic acid (vitamin C), but it exists as a disabled gene (GULOP) in humans and other primates.[26][27] Another more recent example of a disabled gene links the deactivation of the caspase 12 gene (through a nonsense mutation) to positive selection in humans.[28]
It has been shown that processed pseudogenes accumulate mutations faster than non-processed pseudogenes.[8]
Pseudo-pseudogenes
The rapid proliferation of DNA sequencing technologies has led to the identification of many apparent pseudogenes using gene prediction techniques. Pseudogenes are often identified by the appearance of a premature stop codon in a predicted mRNA sequence, which would, in theory, prevent synthesis (translation) of the normal protein product of the original gene. There have been some reports of translational readthrough of such premature stop codons in mammals, as reviewed in the "Translational readthrough" section of the stop codon article. As alluded to in the figure above, a small amount of the protein product of such readthrough may still be recognizable and function at some level. If so, the pseudogene can be subject to natural selection. That appears to have happened during the evolution of Drosophila species, as described next.

Drosophila melanogaster
In 2016 it was reported that 4 predicted pseudogenes in multiple Drosophila species actually encode proteins with biologically important functions,[29] "suggesting that such 'pseudo-pseudogenes' could represent a widespread phenomenon". For example, the functional protein (an olfactory receptor) is found only in neurons. This finding of tissue-specific biologically-functional genes that could have been dismissed as pseudogenes by in silico analysis complicates the analysis of sequence data. As of 2012, it appeared that there are approximately 12,000–14,000 pseudogenes in the human genome,[30] almost comparable to the oft-cited approximate value of 20,000 genes in our genome. The current work may also help to explain why we are able to live with 20 to 100 putative homozygous loss of function mutations in our genomes.[31]
Through reanalysis of over 50 million peptides generated from the human proteome and separated by mass spectrometry, it now (2016) appears that there are at least 19,262 human proteins produced from 16,271 genes or clusters of genes. From this analysis, 8 new protein coding genes that were previously considered pseudogenes were identified.[32]
Examples of pseudogene function
Drosophila glutamate receptor. The term "pseudo-pseudogene" was coined for the gene encoding the chemosensory ionotropic glutamate receptor Ir75a of Drosophila sechellia, which bears a premature termination codon (PTC) and was thus classified as a pseudogene. However, in vivo the D. sechellia Ir75a locus produces a functional receptor, owing to translational read-through of the PTC. Read-through is detected only in neurons and depends on the nucleotide sequence downstream of the PTC.[29]
siRNAs. Some endogenous siRNAs appear to be derived from pseudogenes, and thus some pseudogenes play a role in regulating protein-coding transcripts, as reviewed.[33] One of the many examples is psiPPM1K. Processing of RNAs transcribed from psiPPM1K yield siRNAs that can act to suppress the most common type of liver cancer, hepatocellular carcinoma.[34] This and much other research has led to considerable excitement about the possibility of targeting pseudogenes with/as therapeutic agents[35]
piRNAs. Some piRNAs are derived from pseudogenes located in piRNA clusters.[36] Those piRNAs regulate genes via the piRNA pathway in mammalian testes and are crucial for limiting transposable element damage to the genome.[37]

BRAF pseudogene acts as a ceRNA
microRNAs. There are many reports of pseudogene transcripts acting as microRNA decoys. Perhaps the earliest definitive example of such a pseudogene involved in cancer is the pseudogene of BRAF. The BRAF gene is a proto-oncogene that, when mutated, is associated with many cancers. Normally, the amount of BRAF protein is kept under control in cells through the action of miRNA. In normal situations, the amount of RNA from BRAF and the pseudogene BRAFP1 compete for miRNA, but the balance of the 2 RNAs is such that cells grow normally. However, when BRAFP1 RNA expression is increased (either experimentally or by natural mutations), less miRNA is available to control the expression of BRAF, and the increased amount of BRAF protein causes cancer.[38] This sort of competition for regulatory elements by RNAs that are endogenous to the genome has given rise to the term ceRNA.
PTEN. The PTEN gene is a known tumor suppressor gene. The PTEN pseudogene, PTENP1 is a processed pseudogene that is very similar in its genetic sequence to the wild-type gene. However, PTENP1 has a missense mutation which eliminates the codon for the initiating methionine and thus prevents translation of the normal PTEN protein.[39] In spite of that, PTENP1 appears to play a role in oncogenesis. The 3' UTR of PTENP1 mRNA functions as a decoy of PTEN mRNA by targeting micro RNAs due to its similarity to the PTEN gene, and overexpression of the 3' UTR resulted in an increase of PTEN protein level.[40] That is, overexpression of the PTENP1 3' UTR leads to increased regulation and suppression of cancerous tumors. The biology of this system is basically the inverse of the BRAF system described above.
Potogenes. Pseudogenes can, over evolutionary time scales, participate in gene conversion and other mutational events that may give rise to new or newly-functional genes. This has led to the concept that pseudogenes could be viewed as potogenes: potential genes for evolutionary diversification.[41]
Misidentified pseudogenes
Sometimes genes are thought to be pseudogenes, usually based on bioinformatic analysis, but then turn out to be functional genes. Examples include the Drosophila jingwei gene[42][43] which encodes a functional alcohol dehydrogenase enzyme in vivo.[44]
Another example is the human gene encoding phosphoglycerate mutase[45] which was thought to be a pseudogene but which turned out to be a functional gene,[46] now named PGAM4. Mutations in it actually cause infertility.[47]
Bacterial pseudogenes
Pseudogenes can be found in bacteria.[48] Most are in bacteria that are not free-living; that is, they are either symbionts or obligate intracellular parasites and thus do not require many genes that are needed by bacteria living in changeable environments. An extreme example is the genome of Mycobacterium leprae, the causative agent of leprosy. It has been reported to have 1,133 pseudogenes which give rise to approximately 50% of its transcriptome.[49]
See also
- Molecular evolution
- Molecular paleontology
- Retroposon
- Retrotransposon
References
^ Max EE (1986). "Plagiarized Errors and Molecular Genetics". Creation Evolution Journal. 6 (3): 34–46..mw-parser-output cite.citation{font-style:inherit}.mw-parser-output q{quotes:"""""""'""'"}.mw-parser-output code.cs1-code{color:inherit;background:inherit;border:inherit;padding:inherit}.mw-parser-output .cs1-lock-free a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Lock-green.svg/9px-Lock-green.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-limited a,.mw-parser-output .cs1-lock-registration a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/d/d6/Lock-gray-alt-2.svg/9px-Lock-gray-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-subscription a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/a/aa/Lock-red-alt-2.svg/9px-Lock-red-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration{color:#555}.mw-parser-output .cs1-subscription span,.mw-parser-output .cs1-registration span{border-bottom:1px dotted;cursor:help}.mw-parser-output .cs1-hidden-error{display:none;font-size:100%}.mw-parser-output .cs1-visible-error{font-size:100%}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration,.mw-parser-output .cs1-format{font-size:95%}.mw-parser-output .cs1-kern-left,.mw-parser-output .cs1-kern-wl-left{padding-left:0.2em}.mw-parser-output .cs1-kern-right,.mw-parser-output .cs1-kern-wl-right{padding-right:0.2em}
^ Chandrasekaran C, Betrán E (2008). "Origins of new genes and pseudogenes". Nature Education. 1 (1): 181.
^ Vanin EF (1985). "Processed pseudogenes: characteristics and evolution". Annual Review of Genetics. 19: 253–72. doi:10.1146/annurev.ge.19.120185.001345. PMID 3909943.
^ Chang Y, Stuart A, et al. (2012). "Antigen presenting genes and genomic copy number variations in the Tasmanian devil MHC". BMC Genomics. 13:87. doi:10.1186/1471-2164-13-87.
^ Xiao-Jie L, Ai-Mei G, Li-Juan J, Jiang X (January 2015). "Pseudogene in cancer: real functions and promising signature". Journal of Medical Genetics. 52 (1): 17–24. doi:10.1136/jmedgenet-2014-102785. PMID 25391452.
^ Herron JC, Freeman S (28 December 2006). Evolutionary analysis (4th ed.). Upper Saddle River, NJ: Pearson Prentice Hall. ISBN 978-0-13-227584-2.
^ Jacq C, Miller JR, Brownlee GG (September 1977). "A pseudogene structure in 5S DNA of Xenopus laevis". Cell. 12 (1): 109–20. doi:10.1016/0092-8674(77)90189-1. PMID 561661.
^ ab Zheng D, Frankish A, Baertsch R, Kapranov P, Reymond A, Choo SW, Lu Y, Denoeud F, Antonarakis SE, Snyder M, Ruan Y, Wei CL, Gingeras TR, Guigó R, Harrow J, Gerstein MB (June 2007). "Pseudogenes in the ENCODE regions: consensus annotation, analysis of transcription, and evolution". Genome Research. 17 (6): 839–51. doi:10.1101/gr.5586307. PMC 1891343. PMID 17568002.
^ Mighell AJ, Smith NR, Robinson PA, Markham AF (February 2000). "Vertebrate pseudogenes". FEBS Letters. 468 (2–3): 109–14. doi:10.1016/S0014-5793(00)01199-6. PMID 10692568.
^ van Baren MJ, Brent MR (May 2006). "Iterative gene prediction and pseudogene removal improves genome annotation". Genome Research. 16 (5): 678–85. doi:10.1101/gr.4766206. PMC 1457044. PMID 16651666.
^ Kim, MS; et al. (2014). "A draft map of the human proteome". Nature. 509: 575–581. Bibcode:2014Natur.509..575K. doi:10.1038/nature13302. PMC 4403737. PMID 24870542.CS1 maint: Explicit use of et al. (link)
^ Jurka J (December 2004). "Evolutionary impact of human Alu repetitive elements". Current Opinion in Genetics & Development. 14 (6): 603–8. doi:10.1016/j.gde.2004.08.008. PMID 15531153.
^ Dewannieux M, Heidmann T (2005). "LINEs, SINEs and processed pseudogenes: parasitic strategies for genome modeling". Cytogenetic and Genome Research. 110 (1–4): 35–48. doi:10.1159/000084936. PMID 16093656.
^ Dewannieux M, Esnault C, Heidmann T (September 2003). "LINE-mediated retrotransposition of marked Alu sequences". Nature Genetics. 35 (1): 41–8. doi:10.1038/ng1223. PMID 12897783.
^ Graur D, Shuali Y, Li WH (April 1989). "Deletions in processed pseudogenes accumulate faster in rodents than in humans". Journal of Molecular Evolution. 28 (4): 279–85. Bibcode:1989JMolE..28..279G. doi:10.1007/BF02103423. PMID 2499684.
^ Baertsch R, Diekhans M, Kent WJ, Haussler D, Brosius J (October 2008). "Retrocopy contributions to the evolution of the human genome". BMC Genomics. 9: 466. doi:10.1186/1471-2164-9-466. PMC 2584115. PMID 18842134.
^ Pavlícek A, Paces J, Zíka R, Hejnar J (October 2002). "Length distribution of long interspersed nucleotide elements (LINEs) and processed pseudogenes of human endogenous retroviruses: implications for retrotransposition and pseudogene detection". Gene. 300 (1–2): 189–94. doi:10.1016/S0378-1119(02)01047-8. PMID 12468100.
^ Navarro FC, Galante PA (July 2015). "A Genome-Wide Landscape of Retrocopies in Primate Genomes". Genome Biology and Evolution. 7 (8): 2265–75. doi:10.1093/gbe/evv142. PMC 4558860. PMID 26224704.
^ Schrider DR, Navarro FC, Galante PA, Parmigiani RB, Camargo AA, Hahn MW, de Souza SJ (2013-01-24). "Gene copy-number polymorphism caused by retrotransposition in humans". PLoS Genetics. 9 (1): e1003242. doi:10.1371/journal.pgen.1003242. PMC 3554589. PMID 23359205.
^ Max EE (2003-05-05). "Plagiarized Errors and Molecular Genetics". TalkOrigins Archive. Retrieved 2008-07-22.
^ ab Lynch M, Conery JS (November 2000). "The evolutionary fate and consequences of duplicate genes". Science. 290 (5494): 1151–5. Bibcode:2000Sci...290.1151L. doi:10.1126/science.290.5494.1151. PMID 11073452.
^ Walsh JB (January 1995). "How often do duplicated genes evolve new functions?". Genetics. 139 (1): 421–8. PMC 1206338. PMID 7705642.
^ Lynch M, O'Hely M, Walsh B, Force A (December 2001). "The probability of preservation of a newly arisen gene duplicate". Genetics. 159 (4): 1789–804. PMC 1461922. PMID 11779815.
^ Harrison PM, Hegyi H, Balasubramanian S, Luscombe NM, Bertone P, Echols N, Johnson T, Gerstein M (February 2002). "Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22". Genome Research. 12 (2): 272–80. doi:10.1101/gr.207102. PMC 155275. PMID 11827946.
^ Zhang J (2003). "Evolution by gene duplication: an update". Trends in Ecology and Evolution. 18 (6): 292–298. doi:10.1016/S0169-5347(03)00033-8.
^ Nishikimi M, Kawai T, Yagi K (October 1992). "Guinea pigs possess a highly mutated gene for L-gulono-gamma-lactone oxidase, the key enzyme for L-ascorbic acid biosynthesis missing in this species". The Journal of Biological Chemistry. 267 (30): 21967–72. PMID 1400507.
^ Nishikimi M, Fukuyama R, Minoshima S, Shimizu N, Yagi K (May 1994). "Cloning and chromosomal mapping of the human nonfunctional gene for L-gulono-gamma-lactone oxidase, the enzyme for L-ascorbic acid biosynthesis missing in man". The Journal of Biological Chemistry. 269 (18): 13685–8. PMID 8175804.
^ Xue Y, Daly A, Yngvadottir B, Liu M, Coop G, Kim Y, Sabeti P, Chen Y, Stalker J, Huckle E, Burton J, Leonard S, Rogers J, Tyler-Smith C (April 2006). "Spread of an inactive form of caspase-12 in humans is due to recent positive selection". American Journal of Human Genetics. 78 (4): 659–70. doi:10.1086/503116. PMC 1424700. PMID 16532395.
^ ab Prieto-Godino LL, Rytz R, Bargeton B, Abuin L, Arguello JR, Peraro MD, Benton R (November 2016). "Olfactory receptor pseudo-pseudogenes". Nature. 539 (7627): 93–97. Bibcode:2016Natur.539...93P. doi:10.1038/nature19824. PMC 5164928. PMID 27776356.
^ Pei B, Sisu C, Frankish A, Howald C, Habegger L, Mu XJ, Harte R, Balasubramanian S, Tanzer A, Diekhans M, Reymond A, Hubbard TJ, Harrow J, Gerstein MB (September 2012). "The GENCODE pseudogene resource". Genome Biology. 13 (9): R51. doi:10.1186/gb-2012-13-9-r51. PMC 3491395. PMID 22951037.
^ MacArthur DG, Balasubramanian S, Frankish A, Huang N, Morris J, Walter K, et al. (February 2012). "A systematic survey of loss-of-function variants in human protein-coding genes". Science. 335 (6070): 823–8. Bibcode:2012Sci...335..823M. doi:10.1126/science.1215040. PMC 3299548. PMID 22344438.
^ Wright JC, Mudge J, Weisser H, Barzine MP, Gonzalez JM, Brazma A, Choudhary JS, Harrow J (June 2016). "Improving GENCODE reference gene annotation using a high-stringency proteogenomics workflow". Nature Communications. 7: 11778. Bibcode:2016NatCo...711778W. doi:10.1038/ncomms11778. PMC 4895710. PMID 27250503.
^ Chan WL, Chang JG (2014). "Pseudogene-derived endogenous siRNAs and their function". Methods in Molecular Biology. 1167: 227–39. doi:10.1007/978-1-4939-0835-6_15. PMID 24823781.
^ Chan WL, Yuo CY, Yang WK, Hung SY, Chang YS, Chiu CC, Yeh KT, Huang HD, Chang JG (April 2013). "Transcribed pseudogene ψPPM1K generates endogenous siRNA to suppress oncogenic cell growth in hepatocellular carcinoma". Nucleic Acids Research. 41 (6): 3734–47. doi:10.1093/nar/gkt047. PMC 3616710. PMID 23376929.
^ Roberts TC, Morris KV (December 2013). "Not so pseudo anymore: pseudogenes as therapeutic targets". Pharmacogenomics. 14 (16): 2023–34. doi:10.2217/pgs.13.172. PMC 4068744. PMID 24279857.
^ Olovnikov I, Le Thomas A, Aravin AA (2014). "A framework for piRNA cluster manipulation". Methods in Molecular Biology. 1093: 47–58. doi:10.1007/978-1-62703-694-8_5. PMID 24178556.
^ Siomi MC, Sato K, Pezic D, Aravin AA (April 2011). "PIWI-interacting small RNAs: the vanguard of genome defence". Nature Reviews Molecular Cell Biology. 12 (4): 246–58. doi:10.1038/nrm3089. PMID 21427766.
^ Karreth FA, Reschke M, Ruocco A, Ng C, Chapuy B, Léopold V, Sjoberg M, Keane TM, Verma A, Ala U, Tay Y, Wu D, Seitzer N, Velasco-Herrera Mdel C, Bothmer A, Fung J, Langellotto F, Rodig SJ, Elemento O, Shipp MA, Adams DJ, Chiarle R, Pandolfi PP (April 2015). "The BRAF pseudogene functions as a competitive endogenous RNA and induces lymphoma in vivo". Cell. 161 (2): 319–32. doi:10.1016/j.cell.2015.02.043. PMID 25843629.
^ Dahia PL, FitzGerald MG, Zhang X, Marsh DJ, Zheng Z, Pietsch T, von Deimling A, Haluska FG, Haber DA, Eng C (May 1998). "A highly conserved processed PTEN pseudogene is located on chromosome band 9p21". Oncogene. 16 (18): 2403–6. doi:10.1038/sj.onc.1201762. PMID 9620558.
^ Poliseno L, Salmena L, Zhang J, Carver B, Haveman WJ, Pandolfi PP (June 2010). "A coding-independent function of gene and pseudogene mRNAs regulates tumour biology". Nature. 465 (7301): 1033–8. Bibcode:2010Natur.465.1033P. doi:10.1038/nature09144. PMC 3206313. PMID 20577206.
^ Balakirev ES, Ayala FJ (2003). "Pseudogenes: are they "junk" or functional DNA?". Annual Review of Genetics. 37: 123–51. doi:10.1146/annurev.genet.37.040103.103949. PMID 14616058.
^ Jeffs P, Ashburner M (May 1991). "Processed pseudogenes in Drosophila". Proceedings: Biological Sciences. 244 (1310): 151–9. doi:10.1098/rspb.1991.0064. PMID 1679549.
^ Wang W, Zhang J, Alvarez C, Llopart A, Long M (September 2000). "The origin of the Jingwei gene and the complex modular structure of its parental gene, yellow emperor, in Drosophila melanogaster". Molecular Biology and Evolution. 17 (9): 1294–301. doi:10.1093/oxfordjournals.molbev.a026413. PMID 10958846.
^ Long M, Langley CH (April 1993). "Natural selection and the origin of jingwei, a chimeric processed functional gene in Drosophila". Science. 260 (5104): 91–5. Bibcode:1993Sci...260...91L. doi:10.1126/science.7682012. PMID 7682012.
^ Dierick HA, Mercer JF, Glover TW (October 1997). "A phosphoglycerate mutase brain isoform (PGAM 1) pseudogene is localized within the human Menkes disease gene (ATP7 A)". Gene. 198 (1–2): 37–41. doi:10.1016/s0378-1119(97)00289-8. PMID 9370262.
^ Betrán E, Wang W, Jin L, Long M (May 2002). "Evolution of the phosphoglycerate mutase processed gene in human and chimpanzee revealing the origin of a new primate gene". Molecular Biology and Evolution. 19 (5): 654–63. doi:10.1093/oxfordjournals.molbev.a004124. PMID 11961099.
^ Okuda H, Tsujimura A, Irie S, Yamamoto K, Fukuhara S, Matsuoka Y, Takao T, Miyagawa Y, Nonomura N, Wada M, Tanaka H (2012). "A single nucleotide polymorphism within the novel sex-linked testis-specific retrotransposed PGAM4 gene influences human male fertility". PLoS One. 7 (5): e35195. Bibcode:2012PLoSO...735195O. doi:10.1371/journal.pone.0035195. PMC 3348931. PMID 22590500.
^ Goodhead I, Darby AC (February 2015). "Taking the pseudo out of pseudogenes". Current Opinion in Microbiology. 23: 102–9. doi:10.1016/j.mib.2014.11.012. PMID 25461580.
^ Williams DL, Slayden RA, Amin A, Martinez AN, Pittman TL, Mira A, Mitra A, Nagaraja V, Morrison NE, Moraes M, Gillis TP (August 2009). "Implications of high level pseudogene transcription in Mycobacterium leprae". BMC Genomics. 10: 397. doi:10.1186/1471-2164-10-397. PMC 2753549. PMID 19706172.
Further reading
.mw-parser-output .refbegin{font-size:90%;margin-bottom:0.5em}.mw-parser-output .refbegin-hanging-indents>ul{list-style-type:none;margin-left:0}.mw-parser-output .refbegin-hanging-indents>ul>li,.mw-parser-output .refbegin-hanging-indents>dl>dd{margin-left:0;padding-left:3.2em;text-indent:-3.2em;list-style:none}.mw-parser-output .refbegin-100{font-size:100%}
Gerstein M, Zheng D (August 2006). "The real life of pseudogenes". Scientific American. 295 (2): 48–55. Bibcode:2006SciAm.295b..48G. doi:10.1038/scientificamerican0806-48. PMID 16866288.
Torrents D, Suyama M, Zdobnov E, Bork P (December 2003). "A genome-wide survey of human pseudogenes". Genome Research. 13 (12): 2559–67. doi:10.1101/gr.1455503. PMC 403797. PMID 14656963.
Bischof JM, Chiang AP, Scheetz TE, Stone EM, Casavant TL, Sheffield VC, Braun TA (June 2006). "Genome-wide identification of pseudogenes capable of disease-causing gene conversion". Human Mutation. 27 (6): 545–52. doi:10.1002/humu.20335. PMID 16671097.
External links
- Pseudogene interaction database, miRNA-pseudogene and protein-pseudogene interaction maps database
- Yale University pseudogene database
Hoppsigen database (homologous processed pseudogenes)- RCPedia - Processed Pseudogene database

